kaspterio code as a hacker
Guava LoadingCache设计和实现解读
前言
这篇博客的侧重点是介绍LoadingCache的设计和实现要点,读完后你会收获
- LoadingCache的核心数据结构以及为什么这么做
- LoadingCache的读写并发控制是怎么实现的
如果你还没有看过LoadingCache的源码,建议先对着代码通读一篇。
Guava LoadingCache功能介绍
LoadingCache是Guava库中最常用的核心功能之一,其定位是作为一个支持多线程并发读写、高性能、通用的in-heap本地缓存。在使用上LoadingCache通过builder模式提供描述式api定制LoadingCache的功能以满足给定场景的需求。其主要功能有:
- 核心功能:高性能线程安全的in-heap Map数据结构 (类似于ConcurrentHashMap)
- 支持key不存在时按照给定的CacheLoader的loader方法进行Loading,如果有多个线程同时get一个不存在的key,那么有一个线程负责load,其他线程wait结果
- 支持entry的evitBySize,这是一个LRU cache的基本功能
- 支持对entry设置过期时间,按照最后访问/写入的时间来淘汰entry
- 支持传入entry删除事件监听器,当entry被删除或者淘汰时执行监听器逻辑
- 支持对entry进行定期reload,默认使用loader逻辑进行同步reload (建议override CacheLoader的reload方法实现异步reload)
- 支持用WeakReference封装key,当key在应用程序里没有别的引用时,jvm会gc回收key对象,LoadingCache也会得到通知从而进行清理
- 支持用WeakReference或者SoftReference封装value对象
- 支持缓存相关运行数据指标的统计
使用示例和更多介绍见guava的文档: CachesExplained
设计要点
基础数据结构
LoadingCache最基础的部分是一个支持多线程并发操作的key-value结构的Map,类似于JDK中大名鼎鼎的ConcurentHashMap,在实现上也借鉴了它:将原来的一个hash表分成多段,所有读写操作都会先寻址到对应的段,在段内进行,这样通过分段锁来避免写操作时锁住整个表(这里借鉴的是ConcurrentHashMap在java8之前的实现,自java8开始ConcurrentHashMap为了进一步提高并发,摒弃了分段锁实现,基于CAS机制直接采用一个大数组,同时为了提高哈希碰撞下的寻址性能,Java8在链表长度超过一定阈值时将链表转换为红黑树)。
在每个段内有个独立的数组作为hash表,采用链表来解决hash碰撞,当hash表容量达到一定阈值时会进行扩容,然后rehash,都是常规操作。
值得注意的是:cache每个段内的写操作是需要加锁的,但是读操作基本都是不加锁的。也就是说对于写操作,同时只允许一个写操作的存在,但是对于读操作是没有限制的,读操作也完全可以和写操作并发进行。
基于容量的淘汰机制
使用分段hash表带来一个问题就是:evitBySize时全局的LRU淘汰就比较难办,实际上LRU淘汰也是在段内进行的,即在初始化时根据总的maxSize计算得到每个段的maxSize,保证每个段内元素大小不超过段内的元素数量限制。另外LoadingCache支持为元素定制一个计算元素权重的Weigher(默认每个元素的权重都是1),淘汰操作保证是段内元素的总weight不超过限制。evitBySize淘汰元素的时机是每当有新元素存入hash表并load完成时,在段的锁保护下进行的。
基于过期时间的淘汰机制
对于过期元素的清理时机,一般来说有两种策略:一种是和正常的数据读写过程隔离,开辟独立的线程来执行定期清理过期元素的工作,这种做法的问题在于1)需要开辟额外的线程 2)清理线程会和用户读写操作线程产生对锁的竞争;另一种策略是将清理元素嵌入到读写操作过程中。LoadingCache在设计上采用的是第二种方案,在每次写操作时都会去尝试执行清理逻辑,在累积一定读操作后也会去尝试执行清理逻辑,以保证在一个少写多读的场景下过期元素也能有机会去清理(另外,在读操作时如果发现元素过期了/被垃圾回收也会触发清理逻辑)。同时LoadingCache也建议在一个写非常少、读非常多的场景下,使用者自行创建一个清理线程执行Cache.cleanUp()来清理过期元素。清理工作分为两部分:一部分是将过期元素从内部各种数据结构里删掉,涉及到对内部数据结构的变更,因此需要在段锁保护下进行;另一部分是执行用户的元素删除事件监听器逻辑,这部分执行的是用户逻辑,可能会有很重的操作,因此必须不能在锁保护下进行,执行前需要释放取到的段锁。
基于java引用的淘汰机制
由于LoadingCache的缓存属性,其内部Map中的Key和Value都可以用Java中Reference类来包装。对于Key支持用WeakReference包装,当Key对象除了Reference之外没有别的地方引用时,下次gc时对象会被回收,同时ReferenceQueue里会收到通知,然后对应的entry会被清理掉。对于Value支持用WeakReference/SoftReference包装,当Value对象没有别处引用时,分别会在下次gc/即将OOM前辈被回收掉,同样对应的ReferenceQueue会收到通知,对应的entry会被清理。 当使用Reference来包装Key/Value时,相等性校验则直接比较的是对象引用地址是否相同,hash计算也是采用native的System.identityHashCode方法。被GC回收元素的清理时机和过期元素的清理时机/过程基本一致。
代码实现分析
LoadingCache的实现细节非常多,主要代码位于LocalCache类中,接近5000行,受限于篇幅,我不打算详细写下每个细节的实现分析。这里挑出几个我感兴趣的、认为比较有意思的问题,然后带着问题去学习代码。
阅读LoadingCache代码的起点是LocalCache的get(K key, CacheLoader<? super K, V> loader)方法,网上已经有很多对整个get方法流程(涉及缓存读写操作)做详细介绍和剖析的文章,推荐Guava Cache源码详解和Guava LocalCache 缓存介绍及实现源码深入剖析这两篇文章,这里我就不重复这个工作了。
我在阅读这块源码时始终带着这个问题:前面也提到了,LoadingCache只有写操作会加锁,读操作是不加锁的,也允许一个写操作和多个读操作的并发执行,怎么做到的?(在1.7的ConcurrentHashMap中也是允许单个写和多个读并发进行,实现分析见深度剖析 JDK7 ConcurrentHashMap 中的知识点,LoadingCache中读写并发的实现机制和ConcurrentHashMap类似,但是有值得说明的区别)
在回答上面问题之前,先梳理下LoadingCache内部的主要数据结构,介绍下其作用。其实很多时候数据结构确定后,实现也就随之确定了。可以说确定其数据结构是最根本的问题所在,而且多年看源码的经验告诉我,只要抓住数据结构这根主线就基本不会迷失在浩瀚如烟的代码细枝末节之中。LoadingCache的数据结构如下图:
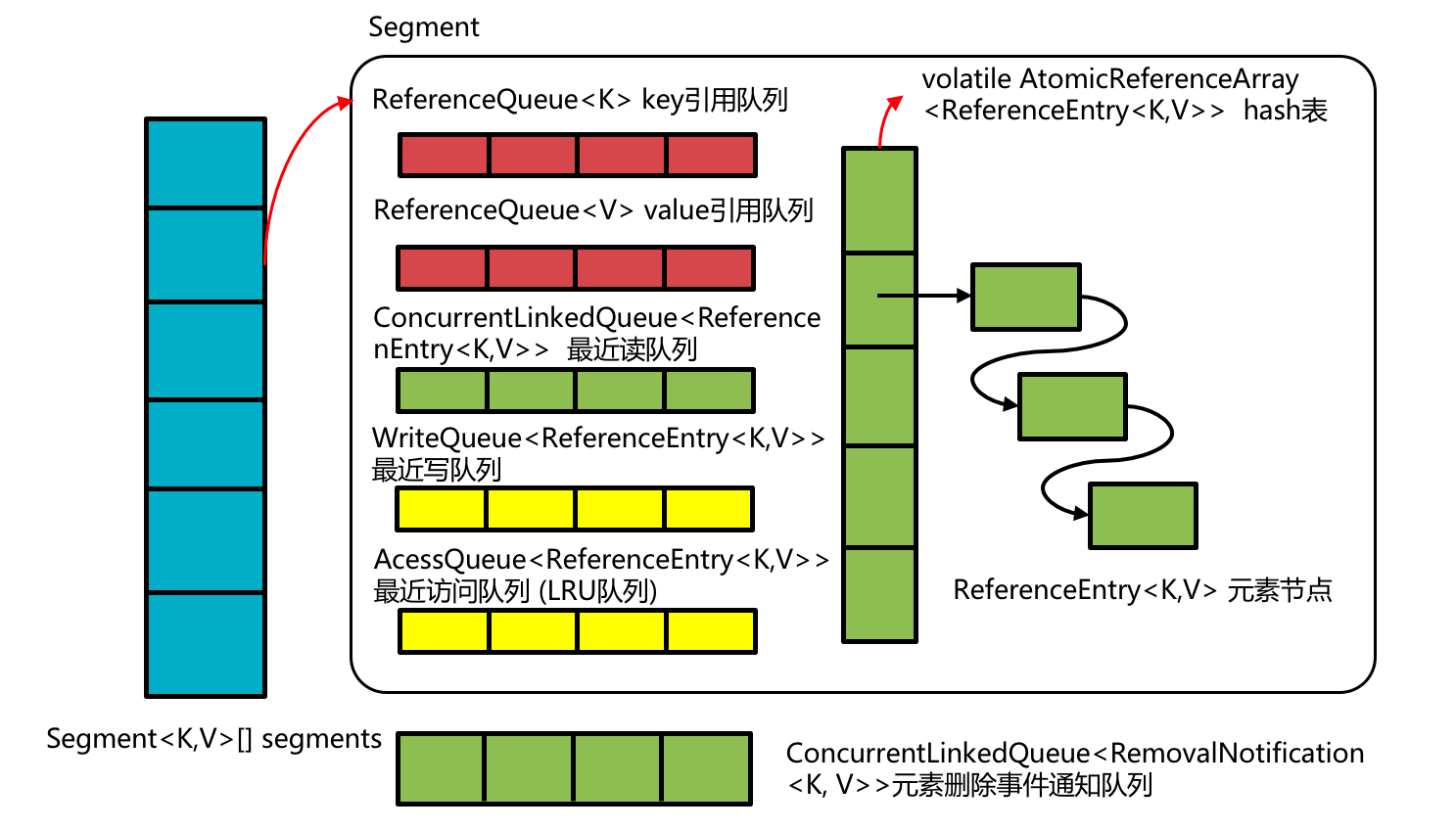
前文提过,LoadingCache内部采用分段锁控实现写并发,每个段(Segment)内有如下几个主要的数据结构:
-
hash表: 最基本的数据结构,hash数组,采用AtomicReferenceArray来实现,这里主要是利用atmoic array的写操作对读的可见性 (unsafe.putObjectVolatile/ unsafe.getObjectVolatile)。hash冲突采用最基本的单链表来解决,所以数组中元素ReferenceEntry有个指向链表下一个元素的指针。
-
key引用队列和value引用队列 如果在build缓存时启用了key/value的引用封装,那么在创建segment时就会初始化对应的这两个队列,用于接收gc回收key/value对象的通知,队列中元素是引用key/value的Reference对象。显然ReferenceQueue是线程安全的,队列的生成者是jvm的gc线程,消费者是LoadingCache自身,消费的时机前面也提过了。消费做的事情就是清理:即hash表中对应key/value相关的entry从hash表中删除(具体代码见drainReferenceQueues方法)。
-
最近写队列 如果build缓存时设置了元素写后过期时间,那么创建segment时就会初始化这个WriteQueue,WriteQueue的实现非常简单,就是一个带头节点的双向循环链表,而且没有考虑任何并发访问。节点对象就是ReferenceEntry本身。注意到hash表里的散列链表节点也是ReferenceEntry,这是一个很常见的技巧:即一个节点对象可能会同时属于多个链表中,不同的链表使用不同的前后节点指针,这个技巧的好处在于给定一个节点entry对象,所有链表都可以做到常数时间的查找和删除(jdk里的LinkedHashMap实现也采用了这个技巧)。由于写操作都会在锁保护进行,因此WriteQueue无需是线程安全的。
- 最近读队列(recencyQueue) 和 最近访问队列(accessQueue/最近LRU队列)
之所以把这二者放在一起,是因为他们密切相关。如果在build缓存时设置了缓存的最大容量或者是为缓存元素设置了访问后过期时间,那么在初始化segment时这两个队列就会被初始化。其中最近读队列是采用的是jdk中线程安全、支持高并发读写的ConcurrentLinkedQueue,队列中存储的元素是ReferenceEntry(注意这和节点是ReferentEntry本身的WriteQueue的区别);最近访问队列采用的则是LoadingCache自己实现的AccessQueue,AccessQueue的实现和前面的WriteQueue基本一致,节点是ReferenceEntry、非线程安全。那么问题来了:为啥需要两个队列来实现LRU功能。要回答这个问题首先得明确在LoadingCache场景下一个LRU队列需求有哪些:1)缓存的场景基本都是读多写少,LoadingCache的读操作要做到的是高性能、lock-free的读,这样就会有多个线程同时读缓存,意味着LRU队列支持多线程高并发写入(调整元素的LRU队列中的访问顺序) 2)LoadingCache中元素可能会因为过期、容量限制、被gc回收等原因被淘汰出缓存,意味着需要从LRU队列中高效删除元素。因此我们需要的是一个支持多线程并发访问的、常数时间删除元素的队列实现。显然一个ConcurrentLinkedQueue不能同时满足这两个需求,Guava给的解就是再增加一个简单的AccessQueue做到常数时间删除元素。具体来说:
- 每次无锁的读操作都会去写而且只会写最近读队列(将entry无脑入队,见方法:recordRead)
- 每次锁保护下写操作都会涉及到最近访问队列的读写,比如每次向缓存新增元素都会做几次清理工作,清理就需要读accessQueue(淘汰掉队头的元素,见方法expireEntries、evictEntries);每次向缓存新增元素成功后记录元素写操作,记录会写accessQueue(加到队尾,见方法recordWrite)。每次访问accessQueue前都需要先排干最近读队列至accessQueue中(按先进先出顺序,相当于批量调整accessQueue中元素顺序),然后再去进行accessQueue的读或者写操作,以尽量保证accessQueue中元素顺序和真实的最近访问顺序一致(见方法:drainRecencyQueue)
关于这个做法有几个明显的问题:
- 如果在写少读非常多的场景下,读写accessQueue的机会很少,大量读操作会在recencyQueue中累积很多元素占用内存而得不到排干的机会。所以Guava为了解决这个问题,为读操作设置了一个DRAIN_THRESHOLD,当累积读次数达到排干阈值时也会触发一次清理操作,从而排干recencyQueue到accessQueue。
- 在高并发场景下,即便是在每次读写accessQueue前做排干recencyQueue操作,也不能保证accessQueue中元素顺序和实际元素访问顺序一致。这个问题也没那么严重,导致的结果无非就是LRU淘汰过程没那么deterministic,对于一个缓存来说也是可以接受。
我的看法是Guava如果能借鉴ConcurrentLinkedQueue所采用的Simple, Fast, and Practical Non-Blocking and Blocking Concurrent Queue算法实现AccessQueue,那么这里使用一个队列就可以搞定了,也不存在上面说的那两个问题,但是实现上要复杂一点,不展开了。
- 缓存元素删除事件通知队列 这个队列存在的意义很明确,为了解耦执行删除元素逻辑和执行删除事件监听器逻辑。因为监听器逻辑是使用者传入的,可能会很重,执行时必须确保没有持有当前段的锁。入队的代码见enqueueNotification,消费队列代码见runUnlockedCleanup。值得注意的是这个队列所有segment共享的一个,也是使用jdk的ConcurrentLinkedQueue来做到高性能并发访问。
接下来开始回答前面提出的LoadingCachce是怎么做到读写并发的。读操作逻辑很简单,常规的hash表元素查找,代码主要见getEntry方法
@Nullable
ReferenceEntry<K, V> getEntry(Object key, int hash) {
for (ReferenceEntry<K, V> e = getFirst(hash); e != null; e = e.getNext()) {
if (e.getHash() != hash) {
continue;
}
K entryKey = e.getKey();
if (entryKey == null) {
tryDrainReferenceQueues();
continue;
}
if (map.keyEquivalence.equivalent(key, entryKey)) {
return e;
}
}
return null;
}
写操作主要有三种:1)写入新元素 2)删除已有元素 3)hash表扩容,下面分别分析这三种场景下写操作怎么和不加锁的读操作进行并发的。
写入新元素
写入新元素时并发控制相关简单,只需要做到新entry写入hash表后,后续的读操作能够立即读到,而且读到的是完整初始化好的entry对象即可。Guava的做法是新的entry作为冲突链表表头写入AtomicReferenceArray的hash表,很容易做到这点,代码在lockedGetOrLoad方法中,如下:
...
if (createNewEntry) {
loadingValueReference = new LoadingValueReference<K, V>();
if (e == null) {
e = newEntry(key, hash, first);
e.setValueReference(loadingValueReference);
table.set(index, e);
} else {
e.setValueReference(loadingValueReference);
}
}
...
删除已有元素
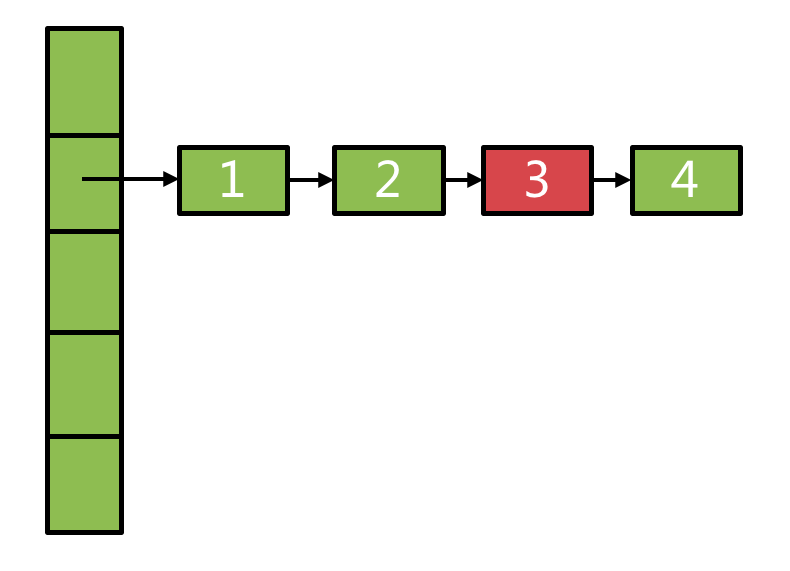
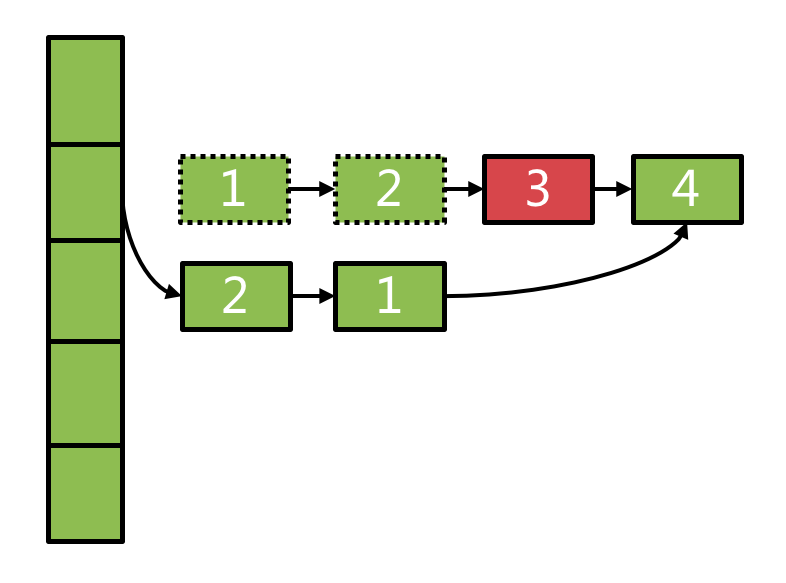
当缓存中元素被淘汰、被gc回收时都会涉及到entry的删除,如果待删除的entry处于冲突链表的中间,如果直接在原链表上进行这个删除操作(对previous的next进行写操作),势必会影响到这个hash桶里的正在进行中的读操作。LoadingCache采用典型的copyOnWrite思想来解决这个问题:当需要删除链表中的某个元素时,不直接在原链表上删除,而是将原链表从表头到待删除元素的前一个节点entry全部copy一份,形成一个新的链表,从而不改变原链表的结构。具体算法设计的有点巧妙,见下:
@GuardedBy("this")
@Nullable
ReferenceEntry<K, V> removeEntryFromChain(ReferenceEntry<K, V> first,
ReferenceEntry<K, V> entry) {
int newCount = count;
ReferenceEntry<K, V> newFirst = entry.getNext();
for (ReferenceEntry<K, V> e = first; e != entry; e = e.getNext()) {
ReferenceEntry<K, V> next = copyEntry(e, newFirst);
if (next != null) {
newFirst = next;
} else {
removeCollectedEntry(e);
newCount--;
}
}
this.count = newCount;
return newFirst;
}
这段代码的效果如下:
假设原hash表链表结构如下图所示,其中3是待删除节点:
执行删除算法后,新的链表结构见下图:
hash表扩容
hash表扩容时读写并发控制处理的思路也是copyOnWrite,具体代码见expand方法:
@GuardedBy("this")
void expand() {
AtomicReferenceArray<ReferenceEntry<K, V>> oldTable = table;
int oldCapacity = oldTable.length();
if (oldCapacity >= MAXIMUM_CAPACITY) {
return;
}
/*
* Reclassify nodes in each list to new Map. Because we are using power-of-two expansion, the
* elements from each bin must either stay at same index, or move with a power of two offset.
* We eliminate unnecessary node creation by catching cases where old nodes can be reused
* because their next fields won't change. Statistically, at the default threshold, only
* about one-sixth of them need cloning when a table doubles. The nodes they replace will be
* garbage collectable as soon as they are no longer referenced by any reader thread that may
* be in the midst of traversing table right now.
*/
int newCount = count;
AtomicReferenceArray<ReferenceEntry<K, V>> newTable = newEntryArray(oldCapacity << 1);
threshold = newTable.length() * 3 / 4;
int newMask = newTable.length() - 1;
for (int oldIndex = 0; oldIndex < oldCapacity; ++oldIndex) {
// We need to guarantee that any existing reads of old Map can
// proceed. So we cannot yet null out each bin.
ReferenceEntry<K, V> head = oldTable.get(oldIndex);
if (head != null) {
ReferenceEntry<K, V> next = head.getNext();
int headIndex = head.getHash() & newMask;
// Single node on list
if (next == null) {
newTable.set(headIndex, head);
} else {
// Reuse the consecutive sequence of nodes with the same target
// index from the end of the list. tail points to the first
// entry in the reusable list.
ReferenceEntry<K, V> tail = head;
int tailIndex = headIndex;
for (ReferenceEntry<K, V> e = next; e != null; e = e.getNext()) {
int newIndex = e.getHash() & newMask;
if (newIndex != tailIndex) {
// The index changed. We'll need to copy the previous entry.
tailIndex = newIndex;
tail = e;
}
}
newTable.set(tailIndex, tail);
// Clone nodes leading up to the tail.
for (ReferenceEntry<K, V> e = head; e != tail; e = e.getNext()) {
int newIndex = e.getHash() & newMask;
ReferenceEntry<K, V> newNext = newTable.get(newIndex);
ReferenceEntry<K, V> newFirst = copyEntry(e, newNext);
if (newFirst != null) {
newTable.set(newIndex, newFirst);
} else {
removeCollectedEntry(e);
newCount--;
}
}
}
}
}
table = newTable;
this.count = newCount;
}
值得一提的是在rehash过程中LoadingCache做了一个很有意思的优化,见代码注释中的那段描述。由于采用的2的整数幂expansion,一个节点在rehash后在新表中的分桶index要么和旧表中的分桶index相同,要么相差个2的整数幂,统计上来说,大约有5/6的节点的next指针是没有改变的,因此原hash表中的某个桶内的冲突链表上可能大部分节点都不需要copy。
总结
受限于篇幅,LoadingCache里还有很多值得学习的设计和实现技巧,比如构建cache的builder模式api、ReferenceEntry的抽象,这里就不一一详细分析了,有兴趣的同学可以自行挖掘。