kaspterio code as a hacker
HPACK explained in detail
Header Compression for HTTP/2
从标题也可以知道,这是一篇关于HTTP2的一个重要特性头部压缩HPACK算法的blog,HPACK在中文互联网上已经有不少HPACK相关的文章,google搜HPACK 算法关键词大概能出来个十来页。大部分都是偏介绍性质,或者一些对RFC 7541、HPACK: the silent killer (feature) of HTTP/2等文章的翻译。其实HPACK的思想很简单,再写篇介绍性质的文章我觉得意义不大,所以这里我将试着从协议设计和实现的角度深入分析HPACK,试着了解HPACK的一些design choices。在进入正题之前,有必要先说下它的诞生背景。
为什么需要Header compression
Patrick McManus曾在In Defense of Header Compresson邮件中给出了header压缩与否对延迟的影响的一些数据,很直观地说明了header压缩的必要性。
在如今的互联网上, 一个页面里通常会包含很多资源,每个资源都会需要http请求去加载,如果每个请求的header大小是1400字节(Cookies, Referer之类的header通常都很大,所以1400字节大小规模并不鲜见),光是要去传输这些headers,可能都需要花费7-8个rtt,造成这一现象的原因是TCP拥塞控制算法的slow start过程。此时如果能对header进行压缩,会很大程度上降低http请求的延迟。
为什么是HPACK
我们知道压缩算法并不是一个新鲜玩意,http对header的压缩为什么不使用已有的类似deflate这种通用压缩算法呢。事实上在http在历史上确实这么干过,比如在很早之前,https中的tls协议承载的应用层数据就是deflate压缩后的header和body数据,http2的前身SPDY协议也采用一个带preset dictionary的类似deflate对header进行压缩,但是这种做法存在严重的安全漏洞,也就是臭名昭著的CRIME攻击。攻击者只要能够做到控制请求里的部分header,就能在多项式时间内通过观测最终请求数据包的大小来恢复出用户浏览器里附带的一些私密header(比如cookie),CRIME之所以能够实施,是因为deflate压缩策略采用的LZ77这种前向字符串匹配压缩算法,攻击者构造header来尝试与已有的header进行字符匹配,如果匹配成功,最终的数据包大小将会减少,匹配的越多,大小减少的也越多。这点信息量的信息泄漏就能足以被攻击者所利用,继而逐步恢复出整个header的value。
另外一点,HTTP header这个场景足够特殊,因为通常来说一个连接上的header都比较固定,数据存在很大的冗余,随着连接上数据交换的进行,header压缩率理论上可以越来越高,因为大部分header都可能在之前出现过。deflate这种通用的压缩算法不能有效利用这个场景知识。
基于这两个原因,http2提出适合http2协议的header压缩算法HPACK。
HPACK Overview
HPACK的基本思想很朴素,朴素到用一句话都能描述。HPACK用一个连接维度的table保存连接上此前出现的header,如果后面再次出现,encoder可以直接使用到table的index来表示这个header,而一个index通常也就一个字节,很大程度上压缩了header。就这样,是不是很简单。。。
这种做法首先在安全性上要好于基于deflate的做法,原因是攻击者不能再通过逐步增加匹配字符串长度的方法来窃取header,虽然攻击者依然可以尝试猜测header value,然后观测压缩后数据包大小的变化,但是对于这种table做法来说,只有完全猜中某个header后数据包大小才会有变化,这样一来,攻击者想要猜测header的计算难度从原来的多项式时间变成指数时间。
另外这种做法显然能够有效利用http2 header这一场景,随着连接上数据的交换,table里可能包含了大部分header。
OK,剩下的问题主要有这几个:
- 1) table显然不能无限大,不然对于http2长连接来说,内存占用将会越来越大。因此需要一种table内entry淘汰机制
- 2) table状态需要在同一个连接上的encoder、decoder两端保持完全同步,不然编解码的数据就会是错的。
- 3) 有些header是http里非常常见,比如”method: GET”, “method: POST”, “accept-encoding: gzip, deflate”… 等等,这些header完全可以事先固定好放到table里,第一次遇到后就能压缩成index。
- 4) 剩下那些不能用index表示的header数据怎么压缩
More detail about HPACK
带着上面的问题,我们就能很容易理解HPACK的工作细节。这里给出一张图来表示HPACK整个压缩和解压大致过程。(对了, 图是我用excalidraw这个工具画的,很香)
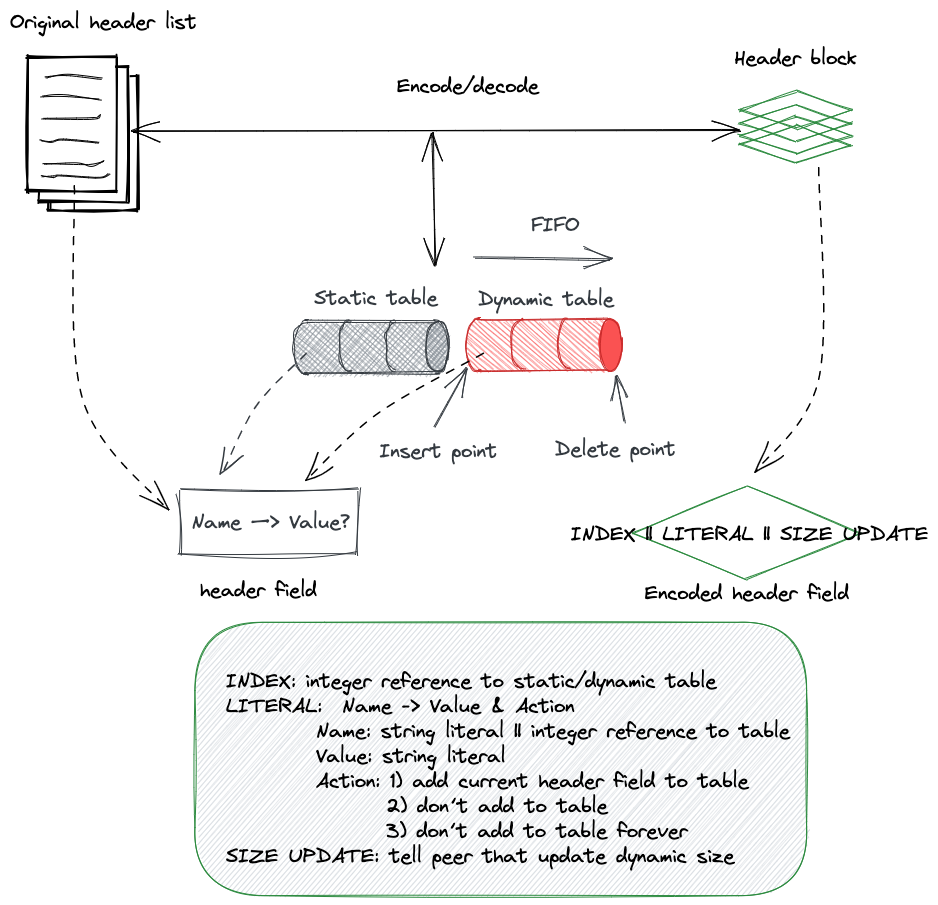
图中中间的那部分就是HPACK在连接维度维护的table,这个table分为两部分,左边的是static table,为了解决问题3),HPACK在协议里规定了61个常见的header,并将其固化到static table中。右边的部分是dynamic table,table entry会随着数据的交新增或者淘汰。
Table capacity limit
HPACK 为dynamic table是有大小限制的,在HTTP2 6.5.2中定义了一种SETTINGS属性SETTINGS_HEADER_TABLE_SIZE, 这个属性用于decoder端告知encoder端(repeat,decoder端告知encoder端),其所允许的最大的dynamic table size(字节数)是多少,encoder端可以选择一个小于等于这个值的大小来作为实际的dynamic table容量,然后encoder端需要在dynamic table容量变动时在header block里和header数据一起通过HEADER帧发送给decoder端,做到dynamic table容量的同步。
SETTINGS_HEADER_TABLE_SIZE这个SETTINGS我觉得可以多说一嘴,SETTINGS里大部分都是用了给sender一方告知 receiver方sender的通信偏好,比如SETTINGS_ENABLE_PUSH作用是sender告诉receiver自己不接受server push,SETTINGS_INITIAL_WINDOW_SIZE作用sender端告诉对端,其能够接受的stream初始窗口大小。SETTINGS_HEADER_TABLE_SIZE则不同,它是decoder端(receiver)告知encoder端(sender)的,这么做其实也很合理,decode一方事先将自己支持的最大table大小告诉encode一方,避免不能对数据进行decode。encoder需要respect这个参数,并将实际采用的table 容量同步给decoder。
OK,既然限制了dynamic table的大小,当向table中加入header field使得超过table容量限制后,就需要将table里现有的header 淘汰出去,这里HPACK采用的FIFO的淘汰方式。
另外注意到协议里有这么一句话:
the encoding and decoding dynamic tables maintained by an endpoint are completely independent, i.e., the request and response dynamic tables are separate.
意味着这个table是有向的,意味着对于HTTP2这种双工协议而言,同一个HTTP2连接上,每个endpoint实际上需要维护两个table, 一个用于encode,一个用于decode。具体来说,对于client而言,encode http request header的table和decode http response header的table是完全分开的。对于sever而言,decode http request header和 encode http response/ server push header也是分开。
Table Synchronization
问题2)里提到table的状态需要在encoder和decoder双端保持同步,这里的状态不仅包括table里的entry (header field),也包括table的容量(不是table的size)。这些状态由encoder同步给decoder,怎么同步呢,HPACK的做法非常简单直接,就和encode后的数据一起发给对端就好了,decoder端接受到数据后,执行和encoder端对应的table状态操作就能使得两端table状态保持一致。
更具体来说,如上图所示,HPACK encoded后的数据有三种,INDEX、LITERAL和SIZE UPDATE。
- INDEX很简单,表示header在table里已存在了,整个header直接用一个到当前table的索引就能表示。 INDEX不涉及table状态变更。
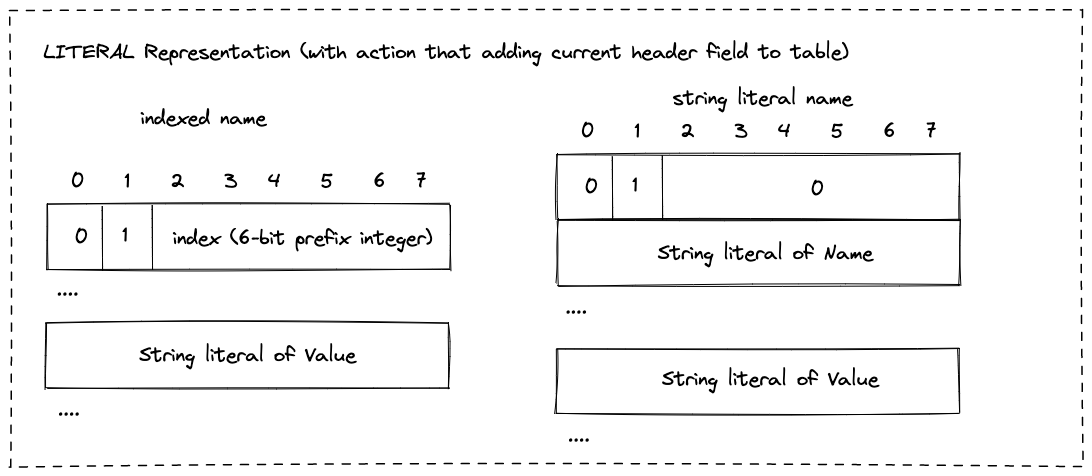
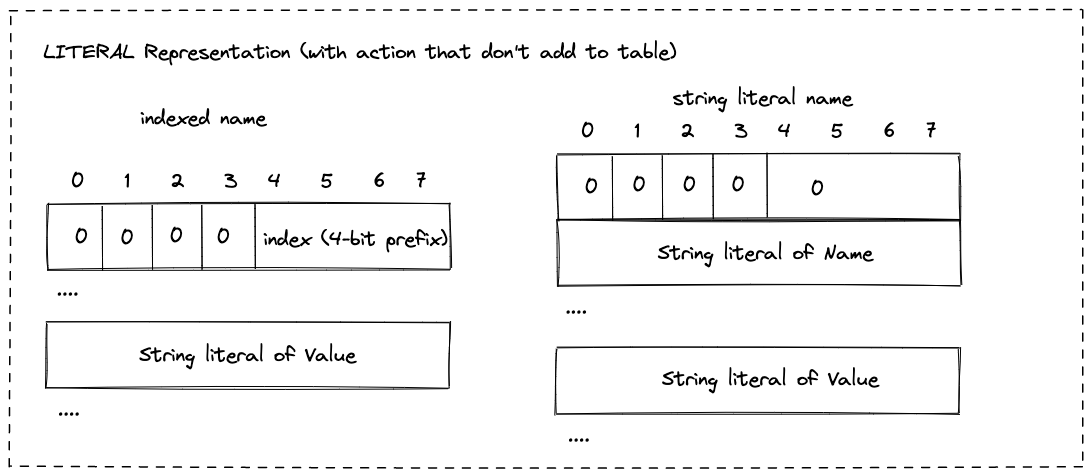
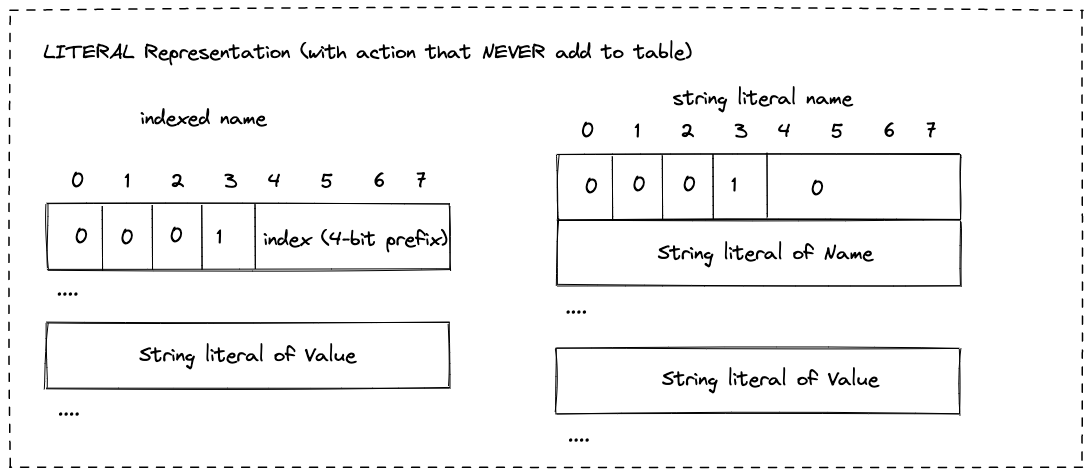
- LITERAL相对复杂些,一个LITERAL header field编码了三个东西: header的name,header的value(可选的),以及对对table状态的action。
- name可以是一个原生的string literal,也可以是一个到当前table的索引
- value可选,如果有值,只能是string literal
- action就是table状态同步操作,有三种分别是:
- 向table中增加当前header field
- 不增加当前header field到table中
- 不增加当前header field到table中,并且任何处理当前header的中间件也不要试图将当前header field加入到table中。
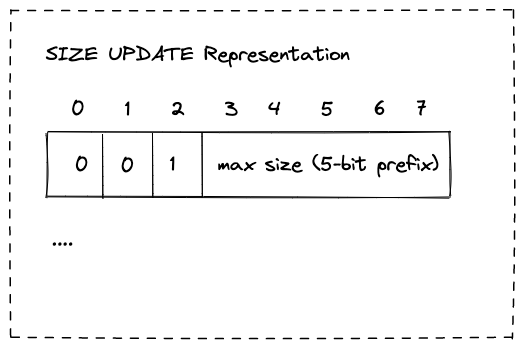
- SIZE UPDATE相对有点特殊,它其实并不是对哪个header的encoded数据,而是对table 容量的同步,作用前面也提到了。
Static Huffman coding
最后一个问题,对于哪些不能用INDEX表示的数据,HPACK允许采用static huffman编码来进行压缩(当然,也允许压根就不压缩)。所谓static huffman编码,其实就是HPACK固定好了一个适用于http header的huffman码表,encoder/decoder直接查表编解码就行了。
关于huffman encoder/decoder的实现这里再多说一点,从算法原理上来看很简单,就是查表,encoder查从byte到code的表,decoder查从code到byte的表。但是从实现上来看,考虑到code是变长的bits,压缩数据由这些变长bits构成由于是前缀编码,每个code中间也没有啥分割标识,而且decoder代码通常是按每个字节来处理压缩数据的,问题就来:怎么去高效地按每个字节decode huffman encoded数据。后面我们将以netty中HpackHuffmanDecoder/Encoder为例,分析下huffman coding的实现。
HPACK data format
至此,我觉得HPACK的工作细节部分就介绍完了。如果你需要自己动手实现HPACK,那么还需要去阅读下RFC 7541中HPACK的编码数据格式部分。这里我对原来文档中的格式部分进行了下二次加工(作图)。感兴趣的话可以参考下。
Integer & String literal
首先是HPACK中定义了两种基本的数据类型,可变长度的integer和string literal。像到table的index、string的长度都是用这个integer来编码表示的。
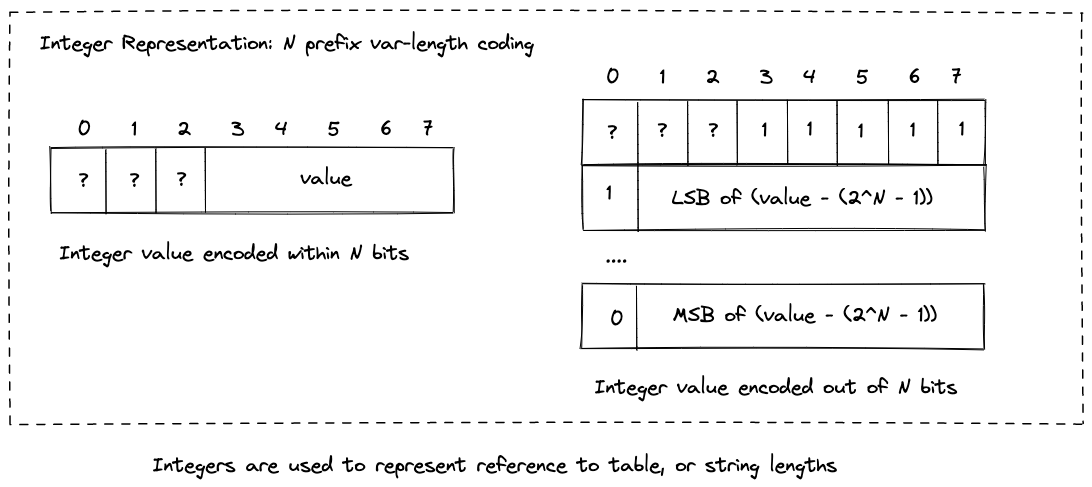
HPACK将其称之为N-prefix coding。值得指出的是integer数据并不一定是开始于整数字节处,可能开始于一个字节(8bit)的任一bit处,从起始位到当前字节的最后一个bit就是这个integer数据的prefix,如果这个integer很小,小到能用prefix bits表示,那么这个integer也就只占用prefix bits。如图左半部分所示。如果这个integer相对大,超出了prefix bits能表示的范围,那么则将prefix bits全置为1,剩下的部分用若干个整数字节表示,每个字节的第一位标识是否是最后一个字节,如图右半部分所示。
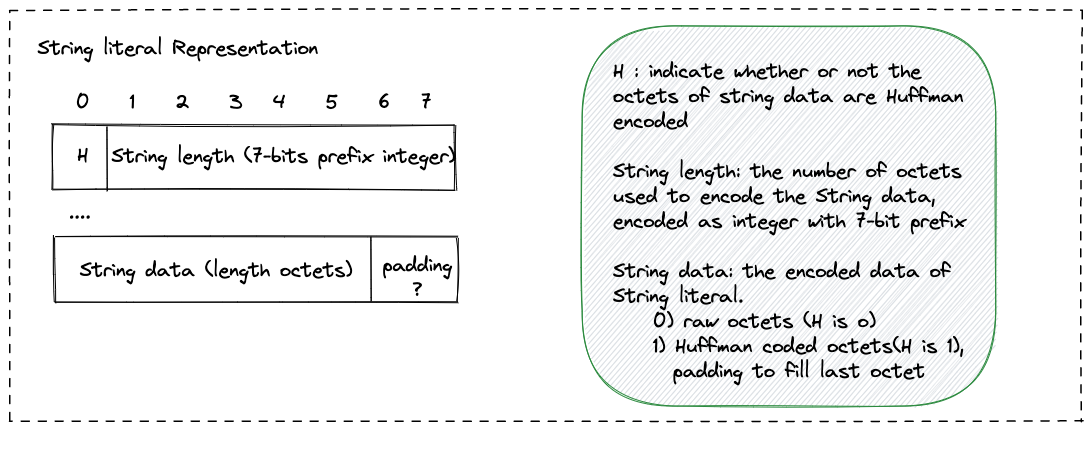
String literal相对简单,由三部分(也可能是四部分)组成:一个bit的标志位,string literal的长度和string literal的data。其中起始标志位用于标识string literal的data是否是huffman coding。
注意到huffman coding是变长编码,当string literal data是huffman coding的化,不一定能在整数字节位处结束,因此可能需要padding到整数字节结束位。
余下格式都比较简单,不多做介绍了。
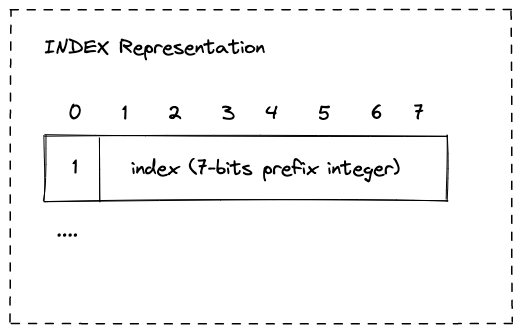
INDEX Representation
LITERAL Representation (with action that adding current header field to table)
LITERAL Representation (with action that don’t add to table)
LITERAL Representation (with action that NEVER add to table)
SIZE UPDATE Representation
总结
可以看出RFC 7541只规定了HPACK压缩数据的格式,以及static table、static huffman coding等内容,有了这些decoder的实现就非常明确了,但是HPACK并没有规定协议实现者怎么实现encoder,只提供了一些安全上的建议,这就给了实现者一些encoder上的自由,比如什么header不能放入table,table的容量控制策略等等,一个好的实现需要考虑这些因素。